非常惨淡的倒在了北京头条的三面上,首先觉得这个提前批的城市选择策略可能有误,太多人投递导致难度激增。第二个就是对操作系统算法的理解有天坑。这里需要弥补一下算法知识和一些深层的概念知识。
一 进程与线程在操作系统内核中的体现
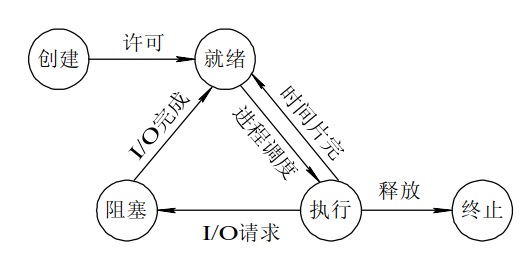
这个问题首先问的是进程和线程是什么样子的,由于前面已经对这个问题进行过总结,所以在此不再进行复述。
然后说实话看到这个问题简直是惊呆了,课程里面确实没有详细学习过linux系统。基于操作系统调度的基本单位是进程,所以当时直接答出来线程应该在内核中没有体现。但是时候查阅资料发现这个问题回答的实在不规范。下面贴出标准答案的回复。
首先需要肯定的是进程和线程在操作系统内核中确实概念相似。在linux系统中,进程和线程或者其他调度单元都是利用 task_struct 这个结构体表示。
1
2
3
4
5
6
7
| struct task_struct {
...
pid_t pid;
pid_t tgid;
...
struct *group_leader;
}
|
进程还是线程的创建都是由父进程/父线程调用系统调用接口实现的。创建的主要工作实际上就是创建task_strcut结构体,并将该对象添加至工作队列中去。而线程和进程在创建时,通过CLONE_THREAD flag的不同,而选择不同的方式共享父进程/父线程的资源,从而造成在用户空间所看到的进程和线程的不同。
引用自Zpeg
然后更加深入的去看待这个问题,无论以任何方式创建进程或者线程,在linux系统中最终都是去调用do_fork()函数。这个函数的原型是:
1
2
3
4
5
| long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
|
- clone_flags是一个标志集合,用来指定控制复制过程的一些属性。最低字节指定了在子进程终止时被发给父进程的信号号码。其余的高位字节保存了各种常数。
- stack_start是用户状态下栈的起始地址。
- stack_size是用户状态下栈的大小。
- arent_tidptr和child_tidptr是指向用户空间中地址的两个指针,分别指向父子进程的PID。NPTL(Native Posix Threads Library)库的线程实现需要这两个参数。
线程跟进程的区别主要就在于do_fork函数首先执行的copy_process中,当上层以pthread_create接口call到kernel时,clone_flag是有CLONE_PTHREAD标识
但CLONE_PTHREAD标识只在最后一个步骤(设置各个ID、进程关系)时体现:(current为当前进程/线程的task_struct结构体 ,p为新创建的结构体对象)
1
2
3
4
5
6
7
| if (clone_flags & CLONE_THREAD) {
p->group_leader = current->group_leader;
p->tgid = current->tgid;
} else {
p->group_leader = p;
p->tgid = p->pid;
}
|
1
2
3
4
5
| const int clone_flags = (CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SYSVSEM
| CLONE_SIGHAND | CLONE_THREAD
| CLONE_SETTLS | CLONE_PARENT_SETTID
| CLONE_CHILD_CLEARTID
| 0);
|
通过判断clone_flags中标记,即可控制子线程会与父线程共享虚拟地址空间、文件、信号等。
本段的内容主要参考了Zpeg的博客,对博客中的部分内容进行精简,透过这里可以简要了解整体的流程。面对面试官的问题可以简要做如下回答:对于系统内核来说,进程和线程没有显著区别,它们在系统中都是一个task_struct结构体,他们的的主要差距是在主进程或者主线程进行系统调用的时候调用了do_fork()函数,然后do_fork函数中执行copy_process。在copy_process中有一个clone_flags,在创建线程的时候clone_flag是据有CLONE_PTHREAD标识的。
二 数据结构 b+树与跳表
b+树的最大优势是可以利用叶子节点相互链接的特性来进行区间查询。这个特性无法被普通排序二叉树前序遍历使用链表链接替代。因为普通排序二叉树使用链表链接时更新下一跳的系统消耗可能过大。
跳表在非尾部进行插入删除时更新索引开销较大。这里与排序二叉树链表链接时更新下一跳类似。
关于这两个数据结构更多的内容不再进行展开描述。具体可以参考各大搜索引擎的介绍(推荐google)
三 深度学习lstm如何解决梯度爆炸
这个问题我很吃惊,毕竟确实是本科生,制作深度学习模型的时候通常都是进行调库调试等操作。所以这里暂时不对这个模块进行扩展。来日方长,如果日后从事算法研究再战。
四 socket编程epoll模型的具体实现
针对select模型和epoll模型,前段时间已经有过了解,select模型是通过轮询来获取活跃的连接的。但是仅知道epoll模型不会轮询所以效率高,但是并不了解epoll模型内部具体实现,这里对epoll模型内部实现机制进行一点介绍。
1
| int epoll_create(int size);
|
首先我们需要关注的是epoll的创建函数,参照晚风_清扬的博客对该函数进行下面的描述。
epoll_ create时,内核除了帮我们在epoll文件系统里建了新的文件结点,将该节点返回给用户。并在内核cache里建立一个红黑树用于存储以后epoll_ctl传来的需要监听文件fd外,这些fd会以红黑树节点的形式保存在内核cache里,以便支持快速的查找、插入、删除操作。
1
| int int epoll_ctl(int epfd, intop, int fd, struct epoll_event *event);
|
内核还会再建立一个list链表,用于存储事件就绪的fd。内核将就绪事件会拷贝到传入参数的events中的用户空间。就绪队列的事件数组events需要自己创建,并作为参数传入这样才可以在epoll_wait返回时接收需要处理的描述符集合。
当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可。
1
| int epoll_wait(int epfd,struct epoll_event *events,int maxevents, int timeout);
|
所以epoll模型的整体工作流程如下:
- 执行epoll_create时,创建了红黑树
- 执行epoll_ctl时,创建就绪list链表,如果增加fd添加到红黑树上,然后向内核注册有事件到来时的回调函数,当设备上的中断事件来临时这个回调函数会向list链表中插入就绪的fd。
- 执行epoll_wait时立刻返回准备就绪链表里的数据即可
这里真的是吃了一个没有学过网络编程的亏,所有的内容几乎都是面试前突击的,但是通过这样重重面试对这些模型内部细节逐步有了一个清晰的认识。
五 linux copy-on-write特性
其实很想跟面试官说,我真的真的真的没有系统的学习过linux操作系统,但是确实我学没学过跟你需要什么样的人才没有啥关系,只能吃一个哑巴亏回去赶紧补着点。
copy-on-write 简单来说就是写时拷贝技术,该技术的主要目的时减少fork时复制主进程内存内容的时间开销。linux系统调用fork函数时,当进程未对内存内容进行修改的时候,此时将直接共享主进程的内存,此时子进程仅拥有对内存进行只读的权限。当需要对内存内容进行修改的时候,操作系统会先将内存copy一份,然后再进行写操作。
在页根本不会被写入的情况下—举例来说,fork()后立即调用exec()—它们就无需复制了。fork()的实际开销就是复制父进程的页表以及给子进程创建惟一的进程描述符。
六 连续抛硬币问题
问题描述:
连续抛硬币,问出现正反反 和反反正的概率谁的更大概率是多少。
面试的时候脑子有点糊,但是最后还是做出来了。分析过程大致如下:
首先考虑下面四种情况:
1/4 NN
1/4 NF
1/4 FN
1/4 FF
我们可以快速的发现,如果出现了正,后续只可能出现正反反胜利的情况。所以反反正胜利的概率仅存在于前两次抛出反的情况。然后对于情况反反,只要出现一次正,则反反正胜利,所以正反反胜利的概率则是 1-1/4 = 3/4。 反反正的概率是1/4。
七 LRU最近替换算法 O(1)
看到这个问题实在是脑壳疼。操作系统课程上对这个内容学习的欠缺导致现在尴尬的局面。这个问题的解决非常非常的简单,利用一个映射数组和链表即可完成o(1)的更新和O(1)的访问。当然也可以利用hash_map和链表。个人推测cpu如果采用这种更新策略,应该使用的是映射数组的方式,这种方式更为稳定。这里需要 内存大小/页大小 的映射空间,在内存过大的时候可能并不是特别实用,所以推测现代cpu应该抛弃了这种方法,但是LRU算法仍然作为最经典的缓存算法被大家使用。
因为心情郁闷这里就不对这个算法重新进行实现,摘选一个接近正确的代码放在下面:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| #include<bits/stdc++.h>
using namespace std;
typedef long long LL;
const int maxn=500005;
int n,m,x,cnt,stk[110],pos[maxn];
int main(){
while(cin>>n>>m){
cnt=0;
memset(pos,0,sizeof(pos));
while(m--){
cin>>x;
if(pos[x]){
for(int i=pos[x];i<cnt;++i)stk[i]=stk[i+1],pos[stk[i]]=i;
stk[cnt]=x,pos[x]=cnt;
}
else{
if(cnt!=n)stk[++cnt]=x,pos[x]=cnt;
else{
for(int i=1;i<n;++i)stk[i]=stk[i+1],pos[stk[i]]=i;
stk[n]=x,pos[x]=n;
}
}
}
for(int i=1;i<=cnt;++i)cout<<stk[i]<<(i==cnt?'\n':' ');
}
return 0;
}
|
然后关于这次心态崩坏的头条三面就总结到这里了,希望能够尽快顺顺利利的获得一个保研offer或者薪水客观的校招offer。加油!!!!!!