
在C++中,单例模式是一种非常常见的设计模式。单例模式主要需要实现下面的两个功能。
- 不能在外部通过构造函数构造,否则一个类将会被多次初始化。
- 每一个对象只能产生一个实例。
1 | 脑壳疼 缓更。 |
在C++中,单例模式是一种非常常见的设计模式。单例模式主要需要实现下面的两个功能。
1 | 脑壳疼 缓更。 |
按理来说学习多线程编程应该从深入浅的来学,但是由于学习的内容实在是有一些偏差,所以最后还是决定从stl标准库开始,学习C++多线程编程。
相比pthread,C++11提供了一个调用非常简单的多线程库std::thread。std::thread的构造函数方便得出人意料,这得感谢std::bind这个神奇的函数。在std::thread的构造函数里,你可以直接传递一个函数和这个函数的参数列表给这个线程。你甚至可以传递一个类成员函数。如果你这么做了,参数列表的第二个参数(第一个参数是被传递的成员函数)会被作为该类成员函数所作用的实例。
1 | // 假设buy是一个可调用的函数对象,它即可能是函数指针,也可能是函数对象 |
1 | pthread_create(&thread, &attr, f, static_cast<void *>(&args)); |
简单的mutex互斥锁实例
1 | #include<iostream> |
在C++中使用volatile关键词可以防止编译器做出错误的优化。当一个线程对一个关键字进行多次读取时,编译器可能会把变量放入寄存器中,而不会每次都从内存中读取,这样如果变量在其他地方修改,会发生脏读取错误。
1 | #include <chrono> |
本文仅简单介绍std::thread的基本操作,更加复杂的操作以及更多的功能将在日后进一步研读。
本文主要记录常见的lambda表达式的用法。
lambda表达式是一个函数,但是它是一个匿名函数,也就是没有名称的函数。通常而言这种函数在代码中仅被调用一次,因此直接在函数内部定义它,以此来提高程序的逻辑性和可读性。
通常而言一个lambda函数展现为下面的形式
1 | [capture](parameters) mutable ->return-type{statement} |
- [capture]:捕捉列表。捕捉列表总是出现在Lambda函数的开始处。实际上,[]是Lambda引出符。编译器根据该引出符判断接下来的代码是否是Lambda函数。捕捉列表能够捕捉上下文中的变量以供Lambda函数使用;
- (parameters):参数列表。与普通函数的参数列表一致。如果不需要参数传递,则可以连同括号“()”一起省略;
- mutable:mutable修饰符,用来说用是否可以修改捕获的变量。默认情况下,Lambda函数总是一个const函数,mutable可以取消其常量性。在使用该修饰符时,参数列表不可省略(即使参数为空); 在值捕获时,加了mutable修饰符,才可以修改捕获变量。尽管可能在表达式的函数体中修改了捕获变量,但由于是值捕获(复制,拷贝),改变了的捕获变量,不影响捕获的变量;没加mutable修饰符时,不能修改;在引用捕获时,不管加不加mutable修饰符,都可以修改捕获变量,由于是引用捕获,原来的捕获变量也改变了。
- ->return-type:返回类型。用追踪返回类型形式声明函数的返回类型。我们可以在不需要返回值的时候也可以连同符号”->”一起省略。
- 如果function body中存在return语句,则该Lambda表达式的返回类型由return语句的返回类型确定;
- 如果function body中没有return语句,则返回值为void类型。
- {statement}:函数体。内容与普通函数一样,不过除了可以使用参数之外,还可以使用所有捕获的变量。
1 | int main(){ |
1 | //包含返回值的lambda表达式与其调用方式。 |
- [] 不捕获任何变量
- [&] 以引用方式捕获所有变量
- [=] 用值的方式捕获所有变量(可能被编译器优化为const &)
- [=, &foo] 以引用捕获foo, 但其余变量都靠值捕获
- [&, foo] 以值捕获foo, 但其余变量都靠引用捕获
- [bar] 以值方式捕获bar; 不捕获其它变量
- [this] 捕获所在类的this指针
1 | int a=1,b=2,c=3; |
1 | vector<string> address{"111","222",",333",".org","wwwtest.org"}; |
1 | #include <iostream> |
C++的第一版发布于98年,但是随着时代的变迁,一些更加现代化的思想也渐渐融入到C++的标准之中,特别显著的就是C++11的版本。今天就简要的介绍C++11的新特性。
在C++11的新标准中,利用nullptr替换了NULL关键字。这个关键词的目的主要是解决0的二义性。我们可以从下面的示例代码简要了解C和C++中NULL通常的定义方式。
1 | #ifdef __cplusplus ---简称:cpp c++ 文件 |
因为在C++中void*不能隐式的转换为其他类型的指针,然后为了为了解决空指针的问题所以特别引入0代表空指针的操作,但是这样的操作在下面的情况就会造成严重的二义性。
1 | void bar(sometype1 a, sometype2 *b); |
为了解决二义性问题,有时候会采取这样的代码来避免二义性,即使用static_cast对0进行显式类型转换。
1 | bar(a, NULL)//××× |
上述的这种操作可以说是异常别扭的。在进行这样特殊的重载时,使用NULL必须使用手动转换,这可以说时让人十分头皮发麻的。所以这里引入nullptr极大程度的解决了这个问题。
1 | bar(a, nullptr)//√√√ C++11 |
使用nullptr可以解决NULL的二义性问题,这可以说是一波让人心情舒畅的操作。
使用using替代typedef的简要代码如下:
1 | typedef double db; |
就个人感觉而言,这种变化带来的最大优势如下:
1 | #define ll long long |
使用typedef感觉会产生巨大的歧义,这句话的含义可以是ll=>long long 但是其实某种意义上也能被理解为 long ll => long??。不得不说这里利用using代替typedef让人无比的舒畅。
不得不说,在C++11中,对于程序员来说最让人欣喜的就是auto关键字。不管从哪方面来看,auto关键字都大大的减少了程序员敲键盘的频率(大雾)。有效的缓解了程序员的肌肉劳损。
auto关键字的最大功能就是推测类型,然后我们还可以利用decltype获取变量的类型,简要的功能代码如下:
1 | auto a = 1; |
上述的代码可以说还是小case,auto关键词最大的优势可能在下面的新特性中:
1 | map<int,int>all; |
可以说简直让人爽到原地起飞,如果说map里面的类型名非常的长,这个时候利用auto就可以顺利的避开敲这么一长串。当然部分开发领域为了保证阅读时语义清晰,还是会采用上面的写法,but很显然下面的写法逐渐成了主流,毕竟python里面迭代一个容器只需要下面的代码:
1 | a = [1, 2, 3, 4, 5] |
虽然不知道这种迭代方式最初源自于哪个语言,但不得不说这是C++的一大进步。
一般来说我们采用一个非常简单的方法来判断一个值是左值还是右值:看能不能对表达式取地址,如果能,则为左值,否则为右值。对于C++11来说右值引用主要是为了拯救函数的返回值。
通常来说一个函数的返回值会销毁掉,比如下面的这个函数:
1 | int add(int a,int b){ |
这个函数返回的是一个临时变量,他在运算结束后就会被销毁。如同上面的变量C,它是利用add函数的返回的临时变量给自己赋值,然后临时变量在运行完该行代码后会被销毁。在C++11之前,为了减少这样的开销,通常人们会采用神奇的常用左值引用的办法。
1 | int main(){ |
这样的操作虽然可以延长返回值的生命周期,但是缺点也是显而易见的,变量c的值可能被固定不能修改。
1 | int main(){ |
使用&&后可以使add的返回值重获新生。该返回值将会一直存活下去直到c变量消亡。
move其实是右值引用相关的内容,但是由于内容规划的问题不知道如何衔接了,所以特别开出另外一个板块。move的作用之一就是将一个左值转换成右值。主要用于下面的情况。
1 | // 构造函数 |
首简要贴出三种构造函数。
1 | vector<Mystring> vec_str; |
通过自定义的类我们可以发现,前一段代码调用了拷贝构造函数,而后一段代码调用了移动构造函数。
最后作为总结贴出一个利用move的特性构造的swap。在类定义了移动拷贝函数时,这种方式将大大降低开销,在没有定义时它跟普通函数相似。
1 | template <typename T> |
这篇东西是在晚上睡不着觉但是又不想刷手机的时候查资料敲出来的,不知道有没有错,但是其实是知道关于右值引用的部分写的是有一定的欠缺的。倘若未来有幸使用C++11进行真正的工程时间,必将把该部分继续完善。頑張りましょう~
面向对象程序设计(object-oriented programming)是一个非常重要的概念,其核心思想是数据抽象、继承、动态绑定。在C++语言中,虚函数的作用是实现多态性。而纯虚函数则作为一个没有具体实现的虚函数,与java程序设计的influence非常相似。今天本篇文章将简要总结C++中的虚函数,并且深入研究C++虚函数的底层实现方式。
本文共分为四个部分 虚函数、纯虚函数、动态绑定、虚函数底层实现
在C++中,虚函数的作用就是为了实现多态性,即父类为子类提供虚函数的默认实现。子类可以重写虚函数以实现自身的特殊化。一段最基本的包含虚函数的父类定义及子类定义如下:
1 | class A |
基于上述的代码,我们将得到“B(output):hello”的输出,注意一旦我们定义一个函数为虚函数,那么它将一直作为虚函数,子类无法改变该函数是虚函数这个事实。
在C++中,如果一个类包含纯虚函数,那么这个类将成为一个抽象类。抽象类无法创建出对象,只有继承了抽象类的子类通过实现虚函数才能被实例化。纯虚函数的概念与java中的influence非常相近,它是一种只提供声明不提供实现的约束。子类需要一一将其全部实现。一个常见的纯虚函数实现如下:
1 | class A |
如果不想实现一个纯虚函数,那么继承它的类也将是一个抽象类。这个范例如下:
1 | class A |
在了解虚函数的底层实现之前,首先需要了解的是动态绑定概念。
- 在执行期间(非编译期)判断所引用对象的实际类型,根据实际类型(动态类型)调用相应的方法。
- 动态绑定灵活性相对静态绑定来说要高,因为它在运行之前可以进行选择性的绑定,但同时,动态绑定的执行效率要低些,因为绑定对象还要进行编译(现在编译期一般都会多次编译)。
触发动态绑定的条件:- (1)只有指定为虚函数的成员函数才能进行动态绑定;
- (2)只有通过基类的指针或引用进行函数调用。
了解了这个关键点后,我们发现我们需要去了解的重点是,如何进行动态绑定的概念,此时就涉及到了C++虚函数的底层实现。
简单查阅资料我们可以发现,C++虚函数的实现主要利用了虚函数表。编译器将为实现了虚函数的基类和覆盖了虚函数的派生类分别创建一个虚函数表(Virtual Function Table,VFT)。也就是说Base和Derived类都将有自己的虚函数表。实例化这些类的对象时,将创建一个隐藏的指针VFT*,它指向相应的VFT。可将VFT视为一个包含函数指针的静态数组,其中每个指针都指向相应的虚函数。Base类和Derived类的虚函数表如下图所示:
1 | class Base |
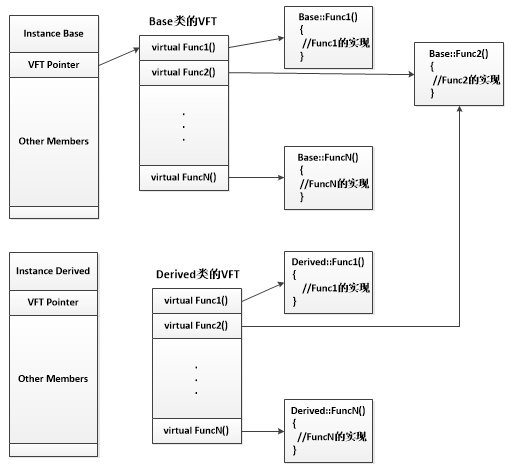
如上图所示,利用上述代码编译后,编译器将会为base类和derived类提供虚函数表。当一个对象被实例化时,将会创建一个隐藏的指针指向对应的虚函数表,从而实现运行时多态。
常常被人问到,会不会写C++,曾经以为了解对面对象编程,了解qt等开源的库之后,就可以称之为会写C++了。但是深入了解之后就会发现,C++其实并不是这么简单。作为本专题的第一篇记录,将从内存分配机制开始深入的剖析C++。
在C++中内存被分为五个区分别是:堆、栈、自由存储区、全局/静态存储区、常量存储区。
- 栈:是分配给函数局部变量的存储单元,函数结束后,该变量的存储单元自动释放,效率高,分配的空间有限。
- 堆:由new创建,由delete释放的动态内存单元。如果用户不释放该内存,程序结束时,系统会自动回收。
- 自由存储区:由malloc创建,由free释放的动态内存单元,与堆类似。
- 全局(静态)存储去:全局变量和静态变量占一块内存空间。
- 常量存储区:存储常量,内容不允许更改。
引用自ladybai
一般而言对于程序员,我们只需要去关注堆和栈的概念。相比堆,栈大量减少了内存的碎片问题,并且计算机在系统底层提供专门的指令执行,而new的机制相比更为复杂所以分配效率相较于栈更慢。
根据许多血一般的教训,下列的代码在动态分配内存的时候至关重要。
1 | object* c = new object(); |
但是其实在较新的C++标准中,出现内存分配失败时会抛出
1 | std::bad_alloc |
但是针对这个我们主要需要意识到一个问题,内存的分配可能失败。
为了防止反复的释放内存,C++除了最基本的new操作之外还提供了placement new的操作。下面简单介绍这三种不同的new操作
- 运算符 new = 先调用函数 operator new 分配空间 + 然后调用构造函数。
- 对于operator new 函数内部,他是通过再调用malloc函数,进行空间分配的(当然也可以重写一个自己的空间分配器)。
- placement new 指的是,不进行分配空间,而是在指定的空间上面进行调用构造函数。当然,在析构的时候,也只能显示的调用析构函数。(因为并不是真正的释放空间)
引用自爱秋刀鱼的猫
下面简单给出new的代码。
1 | object* a = new object(); |
那么其实来说就是上面的两种new,然后operator new的含义应该是仅分配内存但是不初始化函数。
针对大多数场景,我们使用普通的new可以完成绝大多数任务。但是极少数情况,我们可能需要反复利用一块极大的内存空间,此时利用placement new可以减少内存空间的申请释放所消耗的时间。
本篇主要简要介绍了C++内存分配的机制,并且了解了针对大块内存反复申请释放采用placement new的操作。本模块将持续更新,介绍更多关于C++更为深入的内容。
Update your browser to view this website correctly. Update my browser now